| Siguiente: Lecciones aprendidas Superior: Mejorando NFS Anterior: Cambios que hemos hecho |
Como ya se ha dicho antes, utilizamos un kernel de Linux versi�n 2.2.12 y un servidor de NFS de espacio de usuario 2.2beta37. No utilizamos el servidor de espacio de kernel porque todav�a estaba en estado experimental y ten�a todav�a algunos errores.
En el kernel del cliente tuvimos que modificar la llamada al sistema
sendfile para que llamase a la operaci�n de copy que a�adimos a la
estructura de operaciones sobre ficheros. En el caso de un
fichero de NFS, este puntero a funci�n apunta a una funci�n llamada
nfs_file_copy. Esta funci�n, prepara los par�metros, recoge el
puntero de fichero y llama a nfs_file_copy que se ocupa de
construir y llamar a la RPC copy, manejando los posibles errores.
Utilizamos la operaci�n de sendfile porque ten�a exactamente el interfaz que necesit�bamos. Sin embargo, sendfile fue creada, como ya hemos explicado antes, con servidores web y sockets en mente. Puede suceder, pues, que haya alg�n detalle de sendfile que no hayamos visto que se encuentre espec�ficamente preparado para funcionar bien en el contexto en el que fue dise�ada aunque por ahora, no nos hemos encontrado con ning�n problema.
Una parte del kernel que fue especialmente ardua de modificar fueron los encapsulados en XDR de los argumentos. El kernel, con el fin de aumentar la eficiencia de estas traducciones, no utiliza un compilador y hay que hacer estas traducciones a mano. Esta es una tarea dif�cil, tanto para depurar el c�digo, como por lo f�cil que es cometer un error.
Otro cambio interesante que realizamos en el kernel cliente es el a�adir soporte para una entrada en el sistema de ficheros de /proc. Esta entrada nos permite cambiar y leer variables en tiempo de ejecuci�n del kernel, pudiendo hacer cosas como habilitar o deshabilitar la llamada a copy. Esta entrada en /proc nos result� absolutamente fundamental a la hora tanto de depurar como de hacer medidas.
En el servidor s�lo tuvimos que modificar nfsd, el demonio de espacio de usuario que hace de servidor de NFS.
Lo �nico que tuvimos que hacer es a�adir la operaci�n copy al programa RPC del servidor. Como el servidor utilizaba para generar las rutinas de traducci�n de XDR y los stubs en C el compilador rpcgen, esto fue tarea f�cil. El procedimiento que seguimos, fue modificar la descripci�n del programa en XDR, compilarlo con rpcgen y escribir la implementaci�n de la rutina copy. Esta rutina, lo �nico que ten�a que hacer era llamar a read y write localmente, haciendo uso del sistema de ficheros.
La aproximaci�n que hemos descrito hasta ahora, ten�a ciertos fallos, que tuvimos que arreglar para que el sistema realmente funcionase. El fallo principal y m�s dif�cil de encontrar fueron los interbloqueos que generaba la existencia de un �nico hilo en el servidor de NFS. Como ya se ha comentado, debido a la existencia de este �nico hilo, si el write era una petici�n hecha mediante una RPC al mismo servidor de NFS que estaba atendiendo la de copy, se generaba un bloqueo del hilo de ejecuci�n consigo mismo. Este fallo fue bastante dif�cil de encontrar porque era un error de dise�o y apareci� en la fase de depuraci�n.
La soluci�n de este problema, que tampoco es tan complicada una vez se ha conseguido localizar, pasa por el dibujo de todos los diagramas de espera que generan las posibles topolog�as durante la ejecuci�n de una llamada a copy, como se puede ver en la figura 3.
Tras ver la figura queda claro que s�lo hay dos casos que nos lleven a bloqueo. Ocurre un bloqueo siempre que el origen y el destino est�n en la misma m�quina. Aunque uno de estos casos (aquel en el que la misma m�quina que exporta los ficheros por NFS es la que los monta y es tambi�n la que origina el copy) pueda parecer extra�o, fue el primero que probamos al hacer el desarrollo en una sola m�quina. El segundo (el caso con dos ordenadores y los ficheros origen y destino en el que no es originario del copy) fue el que hizo que no pudi�semos llamar a sendfile en el servidor.
Para resolver ambos problemas hicimos principalmente dos cosas. La primera de ellas fue llamar a la operaci�n de copy solamente en el caso en que ambos ficheros son remotos. En caso contrario, se har�a el tradicional read/write, como si se hubiese llamado a sendfile sin modificar.
Lo segundo que hicimos fue llamar a write localmente en lugar de utilizar directamente una RPC. De esta forma, si un ordenador no reexporta un fichero que se ha exportado previamente a s� mismo (un caso completamente an�malo), no puede suceder un bloqueo.
Para tomar las medidas utilizamos una red a 10Mb/s interconectando ordenadores con procesadores AMD K6/2 a 300MHz.
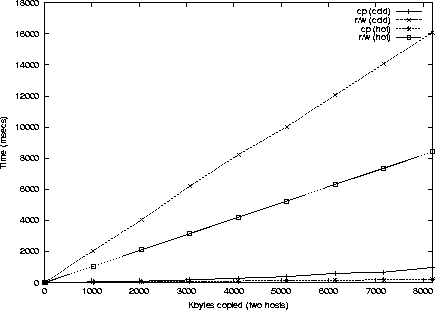
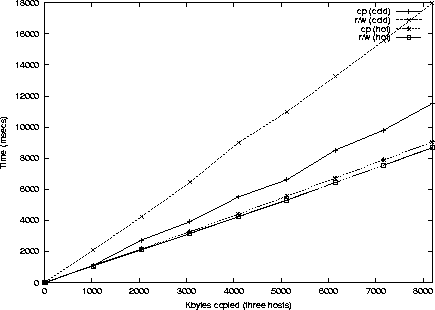
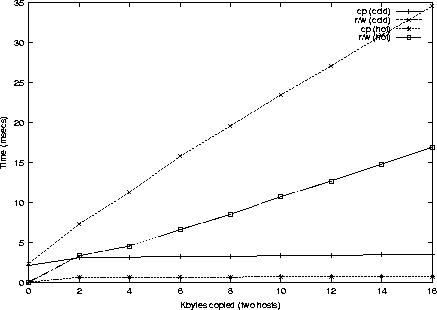
Para tener en cuenta la importancia de la cach�, se hicieron las medidas en unos casos con el fichero en la cach� (cach� ``caliente'') y sin el fichero en la cach� (cach� ``fr�a''). Tambi�n se hicieron medidas para diferentes tama�os de fichero. Los resultados de las medidas se pueden ver en las figuras 4 a 7
Para el caso de dos ordenadores, es obvio que ganamos m�s de un orden
de magnitud en eficiencia al usar la operaci�n de copia frente a
read/write independientemente del estado de la cach�. En el caso de
tres ordenadores, tambi�n obtenemos beneficios si la cach� est� ``fr�a''.
Sin embargo, en el caso de cach� caliente, contrariamente a la
intuici�n es m�s lento usar copy que read/write. Esto es debido a la
combinaci�n de cach� y readahead. A pesar de esto y del alto grado de
uso de la cach� (tiene un porcentaje de uso del ![]() aproximadamente2 habilitamos el caso de tres ordenadores, porque en
media se ganaba en velocidad (aunque fuese poco) y adem�s se reduce
el uso de recursos, memoria, red etc.
aproximadamente2 habilitamos el caso de tres ordenadores, porque en
media se ganaba en velocidad (aunque fuese poco) y adem�s se reduce
el uso de recursos, memoria, red etc.
 |